Kidney health is crucial to our overall well-being, and any obstruction or anomaly in the urinary tract can significantly affect life quality. One such condition is ureteropelvic junction (UPJ) obstruction, which restricts the flow of urine from the kidney to the bladder. Fortunately, with the advancement of medical technology, procedures like Robotic Pyeloplasty Surgery in Delhi have emerged as highly effective solutions. Leading this transformation is Dr. Vikas Agrawal, a renowned urologist with a specialization in robotic and minimally invasive urological surgeries.
Understanding UPJ Obstruction and Its Impacts
UPJ obstruction refers to a blockage at the junction where the kidney meets the ureter. This condition can be congenital or acquired and leads to symptoms such as:
Flank pain
Recurrent urinary tract infections
Kidney stones
Decreased kidney function
Timely diagnosis and treatment are essential to preserve kidney health and prevent permanent damage. Traditionally, open surgery was the go-to method, but now Robotic Pyeloplasty Surgery in Delhi is changing the game.
What is Robotic Pyeloplasty?
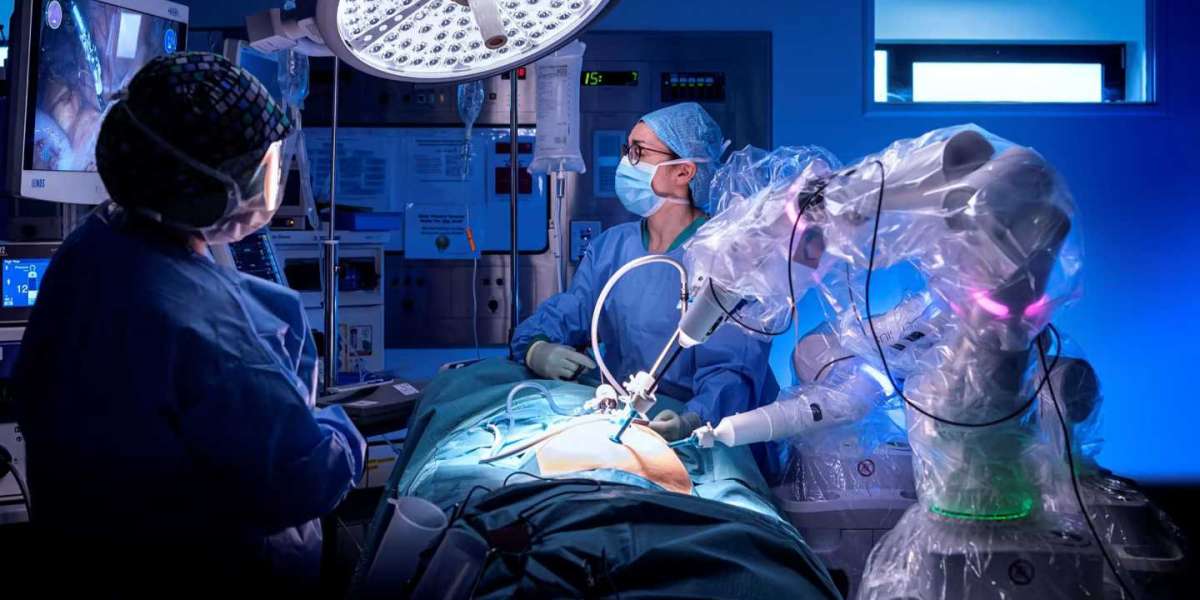
Robotic Pyeloplasty is a minimally invasive surgical technique designed to correct UPJ obstruction. In this procedure, a robot-assisted system—typically the da Vinci Surgical System—is used to provide enhanced precision, 3D visualization, and improved dexterity.
Unlike conventional surgery, robotic pyeloplasty offers:
Smaller incisions
Less blood loss
Reduced pain
Faster recovery
Higher success rates
Patients in Delhi now have access to this advanced technology, thanks to the efforts of specialists like Dr. Vikas Agrawal, who has pioneered robotic urological procedures in the region.
Dr. Vikas Agrawal: A Leader in Robotic Urology
When it comes to Robotic Pyeloplasty Surgery in Delhi, Dr. Vikas Agrawal stands out as a trusted and reputed name. With a deep understanding of complex urological disorders and vast surgical experience, he has successfully performed numerous robotic pyeloplasty procedures with exceptional outcomes.
Key Highlights of Dr. Vikas Agrawal’s Practice:
Robotic Surgery Expertise: Specialized training and certification in robotic-assisted urological surgeries.
Patient-Centered Approach: Personalized treatment plans tailored to individual patient needs.
Advanced Diagnostic Methods: Utilizes cutting-edge diagnostic tools to evaluate UPJ obstruction.
Excellent Success Rate: High patient satisfaction and low complication rates.
His commitment to clinical excellence and innovation has made him one of the most sought-after urologists for Robotic Pyeloplasty Surgery in Delhi.
How the Procedure Works: Step-by-Step
Pre-operative Assessment:
A thorough evaluation including imaging studies like ultrasound, CT scan, or MAG3 renal scan is done to confirm the UPJ obstruction.Anesthesia and Setup:
The patient is placed under general anesthesia. Small incisions are made to insert robotic arms and camera.Surgical Correction:
Using robotic instruments, the surgeon removes the obstructed segment and reconnects the healthy ureter to the renal pelvis.Stent Placement:
A temporary stent may be inserted to maintain the connection during healing.Recovery and Follow-up:
Most patients can go home within a day or two and resume normal activities within a week.
This minimally invasive approach ensures quicker recovery, minimal scarring, and a significantly lower risk of post-operative complications—making Robotic Pyeloplasty Surgery in Delhi the preferred option.
Who Can Benefit from Robotic Pyeloplasty?
Not all patients require surgery, but those who do often benefit greatly from a robotic approach. Ideal candidates include:
Individuals with persistent symptoms due to UPJ obstruction
Patients with decreased kidney function from blockage
Those seeking quicker recovery and minimal pain
Children and adults alike (pediatric robotic pyeloplasty is also possible)
Consulting an expert like Dr. Vikas Agrawal ensures accurate diagnosis and customized treatment, including robotic pyeloplasty if necessary.
These benefits make robotic surgery a game-changer, especially when performed by a skilled surgeon like Dr. Vikas Agrawal.
Cost and Accessibility in Delhi
The cost of Robotic Pyeloplasty Surgery in Delhi may vary depending on the hospital, case complexity, and patient requirements. However, with increasing adoption and government support, the procedure is becoming more accessible.
Dr. Vikas Agrawal consults at premier institutions where robotic surgery is available at competitive pricing without compromising on quality and care.
Patient Success Stories
Many patients who underwent Robotic Pyeloplasty Surgery in Delhi under Dr. Vikas Agrawal have experienced life-changing results. From resolving chronic pain to restoring normal kidney function, the outcomes speak for themselves.
Patients praise Dr. Agrawal for his:
Calm demeanor and clear communication
Surgical precision and attention to detail
Compassionate post-operative care
These testimonials further reinforce why he is one of the best urologists in the field.
Conclusion
If you or a loved one is suffering from ureteropelvic junction obstruction or related kidney issues, exploring Robotic Pyeloplasty Surgery in Delhi is a wise decision. The procedure offers a modern, effective, and minimally invasive solution with high success rates.
Dr. Vikas Agrawal, with his unmatched expertise in robotic urology, ensures each patient receives world-class treatment with a human touch. His commitment to innovation and patient well-being makes him the trusted name for robotic pyeloplasty in Delhi.